Managing backups with git-annex
My Situation
I have backups. Many backups. Too many backups.
I use time machine to back up my macs, but that only covers the systems that I currently run. I have archives of older systems, some for nostalgic reasons, some for reference. I also have a decent set of digital artifacts (pictures, videos and documents) that I’d rather not lose.
So I keep backups.
Unfortunately, I’m not very organized. When I encounter data that I want to keep, I usually rsync it onto one or another external drive or server. However, since the data is not organized, I can’t tell how much of it can simply be deleted instead of backed up again. The actual amount of data that should be backed up is probably less than half of the amount of data that exists on the various internal and external drives both at home and at work. This also means that most of my hard drives are at 90% capacity and I don’t know what I can safely delete.
I really needed a way of organizing the data and getting it somewhere that I can trust.
git-annex
I initially heard of git-annex a while ago, when I was perusing the git wiki. It seemed like an interesting extension but I didn’t take another look at it until the creator started a kickstarter project to extend it into a dropbox replacement.
git-annex is great. It’s an extension to git that allows managing files with git without actually checking them in. git-annex does this by replacing each file with a symlink that points to the real content in the .git/annex directory (named after a checksum of the file’s contents). Only the symlink gets checked into git.
To illustrate, here’s how to get from nothing to tracking a file with git-annex:
$ mkdir repo && cd repo
$ git init && git commit -m initial --allow-empty
Initialized empty Git repository in /Users/nate/repo/.git/
[master (root-commit) c8562e6] initial
$ git annex init main
init main ok
(Recording state in git...)
$ mv ~/big.tar.gz .
$ ls -lh
-rw-r--r-- 1 nate staff 10M Dec 23 15:31 big.tar.gz
$ git annex add big.tar.gz
add big.tar.gz (checksum...) ok
(Recording state in git...)
$ ls -lh
lrwxr-xr-x 1 nate staff 206B Dec 23 15:32 big.tar.gz -> .git/annex/objects/PP/wZ/SHA256E-s10485760--7c8fdf649d2b488cc6c545561ba7b9f00c52741a5db3b0130a8c9de8f66ff44f.tar.gz/SHA256E-s10485760--7c8fdf649d2b488cc6c545561ba7b9f00c52741a5db3b0130a8c9de8f66ff44f.tar.gz
$ git commit -m 'adding big tarball'
...
When the repository is cloned, only the symlink exists. To get the file contents, run git annex get:
$ cd .. && git clone repo other && cd other
Cloning into 'other'...
done.
$ git annex init other
init other ok
(Recording state in git...)
$ file -L big.tar.gz
big.tar.gz: broken symbolic link to .git/annex/objects/PP/wZ/SHA256E-s10485760--7c8fdf649d2b488cc6c545561ba7b9f00c52741a5db3b0130a8c9de8f66ff44f.tar.gz/SHA256E-s10485760--7c8fdf649d2b488cc6c545561ba7b9f00c52741a5db3b0130a8c9de8f66ff44f.tar.gz
$ git annex get big.tar.gz
get big.tar.gz (merging origin/git-annex into git-annex...)
(Recording state in git...)
(from origin...) ok
(Recording state in git...)
$ file -L big.tar.gz
big.tar.gz: data
By using git-annex, every clone doesn’t have to have the data for every file. git-annex keeps track of which repositories contain each file (in a separate git branch that it maintains) and provides commands to move file data around. Every time file content is moved, git-annex updates the location information. This information can be queried to figure out where a files content is and to limit the data manipulation commands.
There is (much) more info in the walkthrough on the git-annex site.
My Setup
What I have is a set of git repositories that are linked like this:
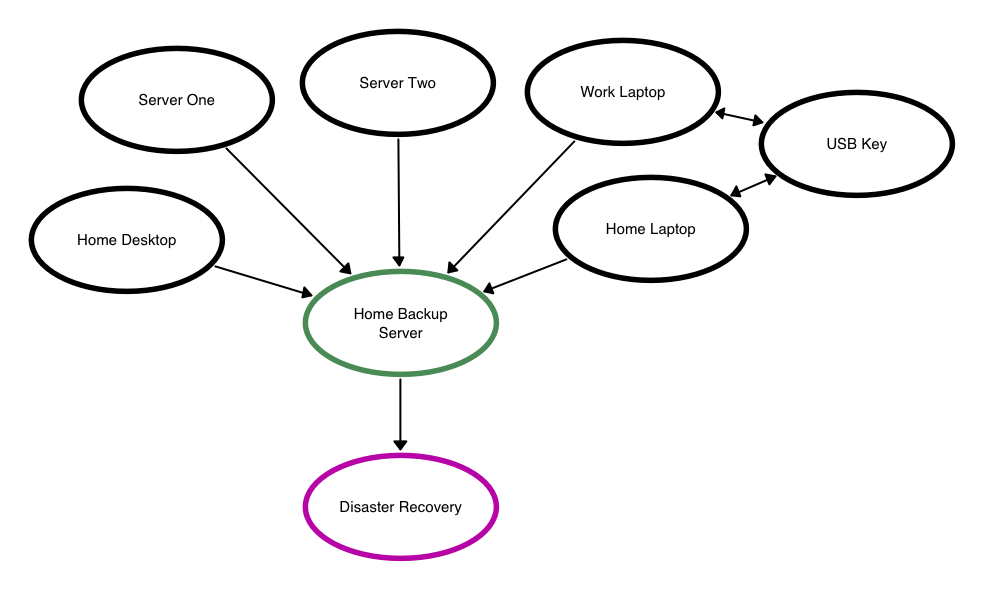
[git-annex has a subcommand to generate a map, but it requires that all hosts are reachable from where it’s run, and that’s not possible for me. I quickly gave up when trying to make my own Graphviz chart and ended up using Lekh Diagram on my iPad (thanks Josh).]
My main repository is on a machine at home (which started life as a mini thumper and is now an Ubuntu box), and there are clones of that repository on various remote machines. To add a new one, all I need to do is clone an existing repository and run git annex init <name> in that repository to register it in the system.
This has allowed me to start organizing my backup files in a simple directory structure. Here is a sampling of the directories in my repository:
- VMs - VM images that I don’t want to (or can’t) recreate.
- funny - Humorous files that I want to keep a copy of (as opposed to trusting the Internet).
- media - Personal media archives, currently mostly tarballs of pictures going back ten years.
- projects - Archives of inactive projects.
- software - Downloaded software for which I’ve purchased licenses.
- systems - Archives of files from systems I no longer access.
There are other directories, and these directories may change over time as I add more data. I can move the symlinks around, even without having the actual data on my system, and when I commit, git-annex will update its tracking information accordingly. Every time I add data or move things around, all I need to do is run git annex sync to synchronize the tracking data.
Here is the simple workflow that I go through when changing data in any git-annex managed repository:
$ git annex sync
$ # git annex add ...
$ # git annex get ...
$ # git annex drop ...
$ git annex sync
With this in place, it’s easy to know where to put new data since everything is just directories in a git repo. I can access files from anywhere because my home backup server is available as an ssh remote. More importantly, I can just grab what I want from there, because git-annex knows how to just grab the contents of a single file.
One caveat to this system is that using git and git-annex means that certain file attributes, like permissions and create/modify/access time are not preserved. To work around this, for files that I want to preserve completely, I just tarball them up and add that file to the git-annex.
Installing git-annex
git-annex is written in Haskell. Installing the latest version on on OS X is not the most repeatable process, and the version that comes with most linux distributions is woefully out of date. So I’ve opted for using the prebuilt OS X app (called beta) or linux tarball.
After copying the OS X app into Applications or unpacking the linux tarball, I run the included runshell script to get access to git-annex:
$ /home/nate/git-annex.linux/runshell bash # on linux
$ /Applications/git-annex.app/Contents/MacOS/runshell bash # on OS X
$ git annex version
git-annex version: 3.20121211
I’ll share more scripts and tips in future blog posts.
Enjoy.