Talk Notes: Raft - The Understandable Distributed Protocol
Summary
Title: Raft - The Understandable Distributed Protocol
Conference: StrangeLoop 2013
Speaker: Ben Johnson
Date: 2013-09-20
http://www.infoq.com/presentations/raft
Notes
Raft PDF: https://ramcloud.stanford.edu/wiki/download/attachments/11370504/raft.pdf Raft homepage: http://raftconsensus.github.io/
Ben wrote goraft, a golang implementation of the raft consensus algorithm.
Distributed consensus used in:
- Data replication
- Leader election - who’s the master
- Distributed locks - share a resource among many nodes
The only other Distributed consensus protocol is Paxos.
Paxos
- Client requests change to Proposer
- Proposer gets a quorum of Acceptors
- Acceptors indicate readyness
- Proposer sends new value to Acceptors
- Acceptors propagate the new value to Learners
- Proposer becomes new Leader
Rather confusing, opaque, lots of roles, often shared. Every new change in the system needs to go through the whole process.
What is Raft
- Created at Stanford by Diego Ongaro and John Ousterhout
- Came out in April/May 2013
- Reference implementation is provided, 28 implementations now
- Commercial use: CoreOS/etcd and go-raft
Basics
Leader Election
Can be thought of as a democratically elected dictatorship.
The cluster is statically defined. Each node needs to know about the size of the cluster and where the other nodes are.
Three players:
- Leader
- Follower
- Candidate
Process:
- Everyone starts off as a Follower
- One node randomly changes into a Candidate and asks for votes from the rest of the cluster
- If a majority of the votes are in favor, then the Candidate becomes the Leader and starts sending out log messages and heartbeats
If the Leader dies, then a random follower will change into a Candidate and the process starts again. If the majority of your nodes are down, then the system is down. If a follower node doesn’t hear a heartbeat message for a certain amount of time (random, between 150 and 300 ms) and then tries to become the leader.
Election terms help disambiguate elections. All nodes operate in the latest term that they’ve heard of. New term is created when a Follower find itself without a leader.
Split vote, when two candidates pop up at the same time. If no node gets a majority, everyone waits for a new election term.
Partitions:
- if a partition occurs where no group has a majority, the cluster is down
- if a partition occurs where one group has a majority, it continues functioning and the smaller group is down till the partition is removed
Question: If a node is partitioned and discovers that it can’t see a quorum after becoming the candidate of a new term, how does it rejoin the group when the partition is removed?
Log Replication
The Leader and all Followers have a log.
The Leader sends out log entries as a heartbeat, with or without new data.
Example:
- Leader gets a new value
- Leader sends log message instructing Followers to append the new value
- When a majority of followers reply that they got the above message, the Leader commits it
- When the next log message goes out, it includes an instruction to commit the new value on the followers because the Leader has
What happens when there’s a partition:
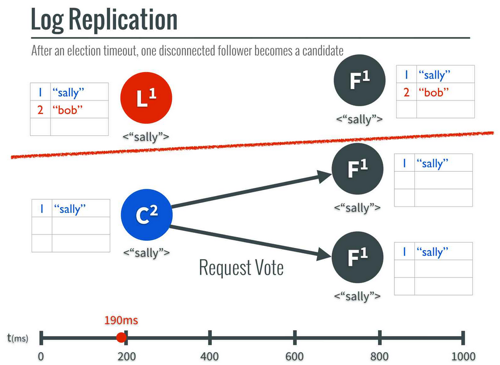
Isolated leader can’t commit values because a majority of nodes aren’t available.
If a new value is sent around in the functional cluster, commits happen as usual.
If the partition is removed, then the old leader steps down and both it and the partitioned follower throw away the uncommitted values (“bob”) and get a new value from the new leader
At minute 22:31, a question from Rich Hickey: How do the clients know which node is the Leader. Answer: It’s not built into the protocol, but one option is to make the location of the leader a value that is persisted via the log and that the client can read.
In a new election in the face of a partition, the new leader will get the most up to date log because a majority of the nodes have to have the most up to date log and that majority will overlap with the majority that is part of the new partition.
Adding nodes: You can add nodes, but that’s a complexity for another talk.
Log Compaction
Unbounded log will take up all disk space, and lso increase recovery time
Three strategies:
- Leader initiated, stored in log
- Leader initiated, stored externally
- Application initiated, stored externally
Diego Ongaro on Raft at RICON West 2013
http://www.youtube.com/watch?v=06cTPhi-3_8
Looking at the raft website pointed me to this talk. Adding notes that clarify the above.
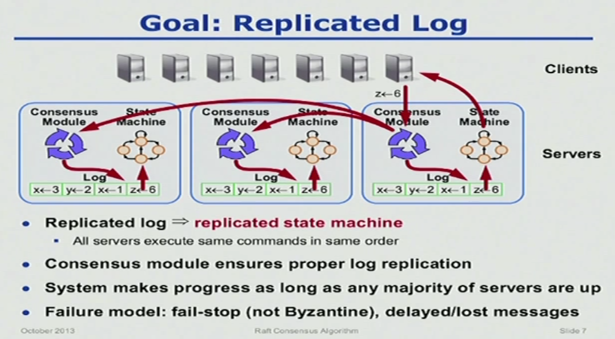
Clients communicate with the leader.
Leader Election
Terms serve to split time into periods of election that is sometimes followed by normal operation, in the case of a successful election
Terms usually end because a leader fails
Getting a message from a higher term leader makes a node stop listening to the old leader.
When no leader, the cluster is unavailable.
Normal Operation
Log structure:
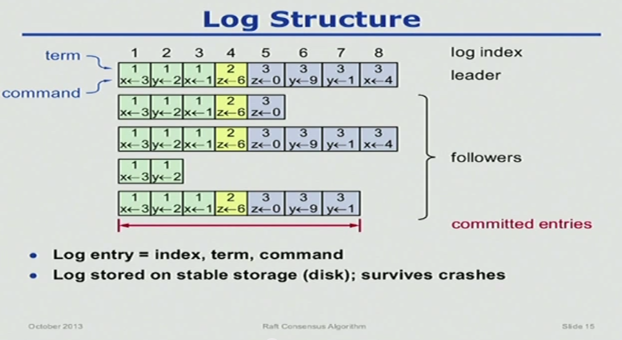
Every committed log entry includes the term that the leader was in when it instructed all nodes to commit it.
Log consistency:

To ensure that committing one entry means the preceding entries can be committed, each append command contains the preceding entry’s index, and so the Follower can prove that the chain of entries is correct by induction.

To fix the Follower logs, the Leader keeps an nextIndex for each Follower. When the Follower rejects the append, the leader steps back and tries again, until it finds one that gets accepted. The Follower deletes everything after the accepted append. Then the Follower requests more entries until it matches the Leader.

Safety
Any two committed entries at the same index must be the same.
If a Leader marks an entry as committed, then the entry will be in every future Leader’s log.
This places restrictions on what gets committed and restrictions on election.
On election
Candidate must have the most up-to-date log among electing majority. Candidates send information about their own log when the request votes:
- Length of log
- Last term
If the voter has a more up-to-date log, then it doesn’t vote for the candidate.
On what gets committed
To commit an entry, the Leader has to hear back from a majority of Followers.
Question: still a little fuzzy on when the Leader can commit and when the Followers can commit.
For a new Leader to mark old entries as committed, it has to commit a new entry from its current term