Talk Notes: Using Datomic with Riak
Summary
Title: Using Datomic with Riak
Conference: RICON East 2013
Speaker: Rich Hickey
Date: 2013-07-31
https://www.youtube.com/watch?v=FOQVWdG5e2s
Notes
Databases can be built on top of one another. RDBMSes tend to be the level 0. Riak CS is built on
Datomic is built on top of various storage engines
Datomic tries to accomplish 2 things:
- Information is something that incorporates time and that accumulates over time
- Change database application model from remote communication to where the database is a regular value in your program
More declarative ORMs are an impedance mismatch, and that’s the programs fault. Databases have been right all along. Need to move the data model further into the program, not abstract it away. Reduce complexity
Datomic tenets:
- The database consists of atomic facts (datoms) (e.g. This is my email, this is no longer my email)
- Keep everything, don’t overwrite
- Query engine is inside your application, not the database engine
- Programming model is declarative and functional
- Immutability
Datomic can’t handle partition tolerance. It keeps strong consistency.
Terms
- Value - immutable
- Identity - Applied to a series of values over time. e.g. ‘my email’, it refers to a different value over time. Identity changes, value does not.
- State - The value an identity has at a particular point in time
- Time - Relative. Things are either before or after other things in the continuum.
Epochal Time Model
- Allows separation of perception and change, allowing you to scale them independently.
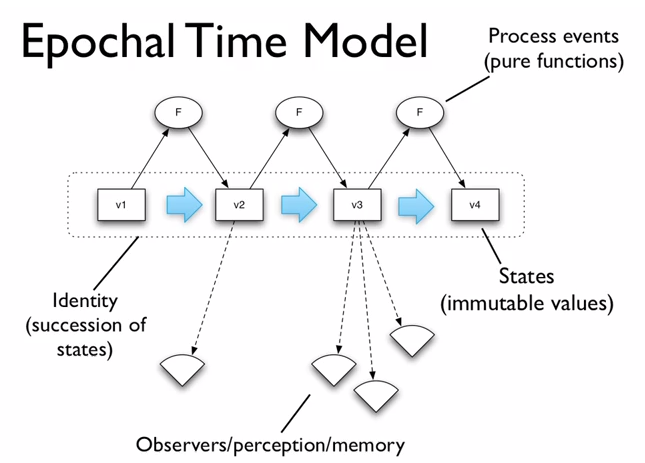
Implementing values
- Persistent data structures
- Implemented via trees
- Structural sharing, to speed up modifications
Traditional databases
Server does: transactions, indexing, I/O, storage, query engine. Client connection is over a tcp connection, very thin.
It’s very hard to scale the do-it-all server. This is place oriented programming. The database is the global variable. The place we go for all information, and we have to go there every time we want any data. Black box.
Goal is to replace it with the Epochal model.
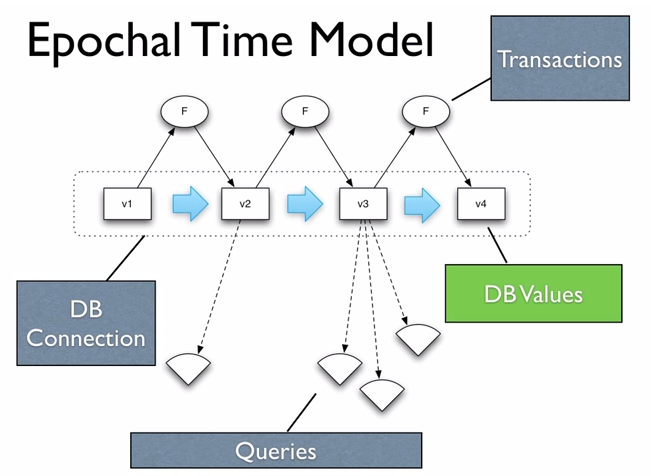
Take all the parts of the do-it-all server and spread them around. Componentized
A bunch of things that do one thing well and combine them together.
Datomic architecture
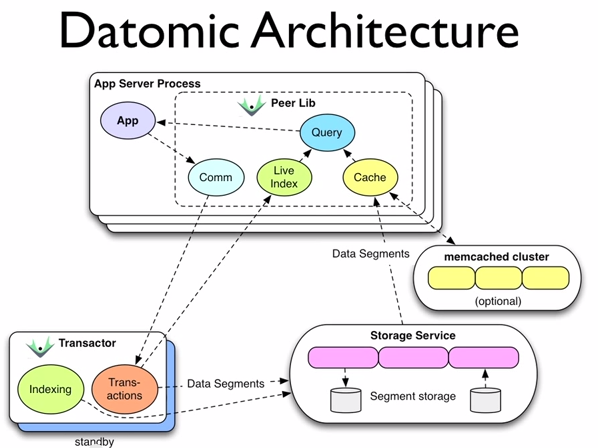
Transactor
Responsible for receiving writes and reflecting them out to the peers. Data is written down in a linear fashion. Also does indexing: takes what’s accumulated in memory and integrates it into the storage, whereupon every peer can drop that accumulation and get a new set of data.
Indexing generates garbage. Like in memory persistent data structures, the new data shares most information with the old data. The difference is, in Datomic, all historical data is in the latest tree, so you don’t have to hold on to old tree roots to keep historical data around. This means that there needs to be garbage collection.
App server process
Able to hit storage directly. Doesn’t go through the transactor.
They have their own query engine. They merge live updates from storage and the transactor so they always have the most up to date data.
Because the data is immutable, caching can be very beneficial. Caching the source of answers to queries, not the queries and answers themselves.
Scalability
- Transactor has the same characteristics as a traditional database. But it doesn’t do queries too, so it has less to do.
- Reads don’t go through transactor, which is closer to the model of the real world.
- Queries scale with peers. Elastic, more peers means more queries.
Index
Complete covering index. Sorted set of datums. Pluggable comparators.
Components of a datum:
- Entity
- Attribute
- Value
- Time
Two sorts always maintained: EAVT and AEVT. Optionally, AVET and VAET sorts can be set up as well, for optimized look up by value.
Reverse index is handled as well when a datum refers to another datum.
The log is a tree, adding nodes on the right side. Indexes are trees as well.
Storage engine
Only need key/value system, so it can be stored anywhere.
Needs to have one value that is strongly consistent: The reference to the immutable data/indexes/etc. This changes at the end of the indexing run, so it needs to be swapped out instantaneously.
Datomic and Riak
Riak is everything that Datomic needs, except for the one piece of strongly consistent data. For that, ZooKeeper is used.
Values go in Riak, Identities go in ZooKeeper.
Uses normal Riak settings for N,W, and DW, but for R, the setting is:
R=1, not-found-ok = false
('first found' semantics)
Most efficient way of reading from Riak. Only works with immutable data. Very fast.
Takeaway: There is an incredible amount of power, and the ability to avoid speculative lookup (vector clocks, merge strategies), if you architect your system to only store immutable data.
Datomic can co-exist with other Riak clients. Doesn’t need its own cluster.
Zookeeper usage
Distributed CAS only for a handful of reference cells per DB. No locks, etc.
Another cluster to maintain. 3-5 servers.
Also can use DynamoDB.
Questions
The transactor is the single observer of the world. Analogous to someone watching a game, taking pictures, and then posting them on the internet. Everyone can then look at the pictures without having to go through the photographer.
Send transaction functions, not absolute statements! Don’t say, “Make Bob’s salary $80,000”, but rather say, “Increase Bob’s salary by $5,000”.